
Nova pesquisa acusa LM Arena de jogar seu popular benchmark de AI

A rápida disseminação dos barcos de bate -papo da IA dificultava saber qual modelo está realmente melhorando e quais está atrasado. Os padrões educacionais tradicionais dizem muito a você, o que fez com que muitas pessoas se curvassem à LM Arena em vibrações. No entanto, uma nova pesquisa afirma que essa popular plataforma de classificação de IA é injusta e é a favor de grandes empresas que ocorrem apenas perto da parte superior do índice. No entanto, os operadores do local dizem que o estudo utiliza resultados incorretos.
A LM Arena foi formada em 2023 como um projeto de pesquisa na UC Berkeley. O arremesso é simples – os usuários fornecem indicações em dois modelos de IA desconhecidos na “bota de bate -papo arina” e estimam a saída para votar sobre o que você gosta. Este número foi depositado no conselho do LM Arena Leader, que mostra quais modelos mais como, quem pode ajudar Melhoria da rastreamento Nos modelos de IA.
As empresas estão prestando mais atenção a essa classificação, pois o mercado de IA é o calor. O Google observou quando lançou o Gemini 2.5 Pro que o modelo estreou na parte superior do Conselho de Líder da LM Arena, onde permanece até o momento. Enquanto isso, o forte desempenho do DIPOC na Chatboat Arena no início deste ano ajudou a ajudar a LLM Ract in the Upper Acel.
Pesquisadores, Kohir Labs, Princeton e MIT pesquisadores acreditam que os desenvolvedores de IA mantiveram muito estoque na LM Arena. O novo estudo, A impressão está disponível no servidor de arquivosAfirma que a classificação de campo é distorcida de maneiras que facilitam a execução de barcos de bate -papo proprietários. Os autores dizem que a LM Arena Maliki permite que os desenvolvedores do Big Language Model (LLM) testem várias versões de sua IA na plataforma. No entanto, apenas o maior desempenho está incluído no conselho de líderes públicos.
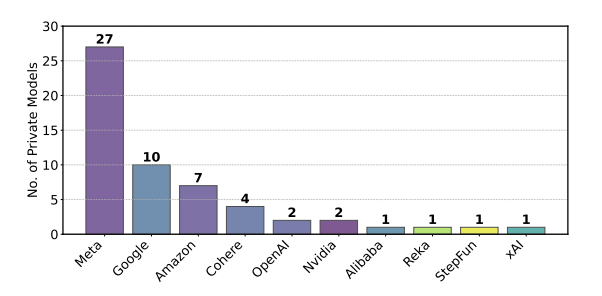
A Meta testou 27 versões do Lilama 4 antes de lançar a versão que aparece no Líder Board.
Crédito: Shivelika Singh, etc.
A Meta testou 27 versões do Lilama 4 antes de lançar a versão que aparece no Líder Board.
Crédito: Shivelika Singh, etc.
Alguns desenvolvedores de IA estão aproveitando a opção de teste privado. Este estudo relatou que a Meta experimentou 27 tipos privados de tipos particulares LLAMA-4 Antes do lançamento, o Google também está aproveitando o sistema de testes privados da LM Arena, que experimentou 10 variações de Gêmeos e Jema entre janeiro e março de 2025.
Neste estudo, a LM Arena também diz que modelos privados como Gemini, Chat GPT e Claude são altamente anunciados. Os desenvolvedores bate -papo coletam dados sobre a conversa do modelo da API da Arena de Boat, mas as equipes que se concentram nos modelos abertos ficam com um final curto do bastão permanentemente.



