
Novas pesquisas mostram por que o modelo de IA de raciocínio artificial ainda não está em seu faturamento


A American Mathematics Olympíade (USAMO) atua como um qualificador para a Olimpíada Internacional de Matemática e oferece mais vezes mais do que testes Exame de matemática de convite americano (Aime) Embora os problemas da AIME sejam difíceis, eles precisam de respostas numéricas. O USAMO exige que os competidores escrevam evidências de matemática completa pontuadas por nove horas e dois dias para precisão, completa e explicação.
Os pesquisadores revisaram vários modelos de raciocínio de IA em seis edições de 2025 USAMOS imediatamente após o lançamento, que fazia parte dos dados de treinamento dos modelos para minimizar qualquer oportunidade. Esses modelos incluíam rainha QWQ-32BPara, para, para,. DPSEC R1Google’s Gemini 2.0 Flash Thinking (experimental) E Gemini 2.5 ProOpenai’s O1-Pro E O3-Mini-AltoAntrópico Claude 3.7 Swant com pensamento expansivoE do zai Grook 3.
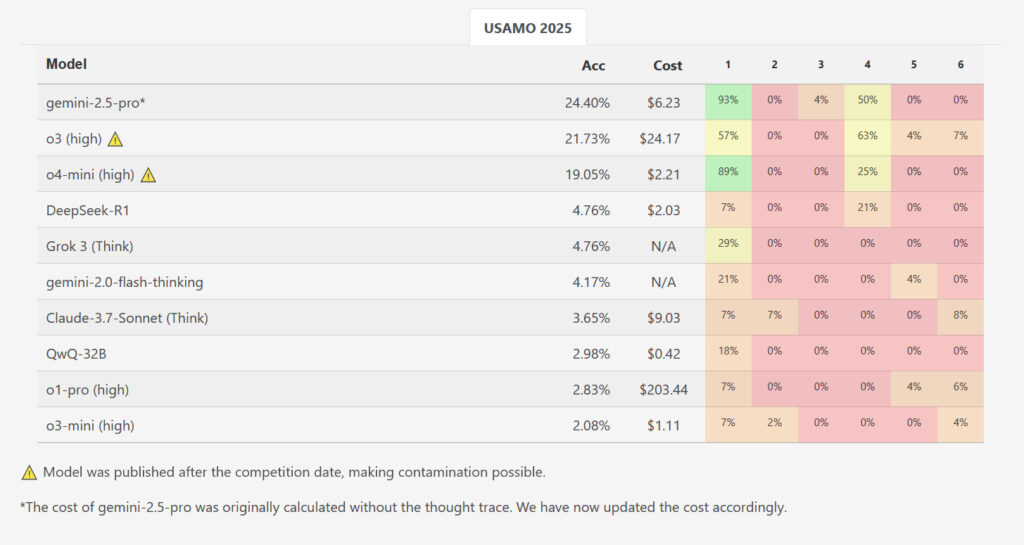
Enquanto um modelo, o Gemini 2.5 Pro do Google obteve uma pontuação média de 10,1 em 42 pontos (~ 24 %), mas os resultados mostraram uma diminuição no desempenho de grande escala em comparação com o benchmark de nível de AIME. Outros modelos de revisão foram deixados para trás: Dipic R1 e Grook 3 ganharam uma média de 2,0 pontos em média 2,0 pontos, o pensamento flash do Google organizou 1,8, o Claude 3.7 da Entrópica, enquanto o QWQ de Kevin e o Openi O-1-Pero têm uma média de 1,2 pontos. O O3-mini da Openi teve uma pontuação média menor em apenas 0,9 pontos (~ 2,1 %). Das quase 200 soluções preparadas em todos os modelos de teste e corridas, nenhum deles tem a melhor pontuação para qualquer problema.
Enquanto o novo lançado do OpenAi 03 e O4-Mini-Alto Não inspecionado para este estudo, os pesquisadores ‘benchmarks’ Luto O site obtém pontuações em três altas 21,73 % no geral e a alta pontuação do OSAMO em 4-Meni no Osamo pontuações 19,05 %. No entanto, esses resultados foram potencialmente contaminados porque foram medidos após a competição, o que significa que os novos modelos de IA abertos podem potencialmente adicionar soluções aos dados de treinamento.
Como os modelos falharam
No artigo, os pesquisadores identificaram várias amostras importantes de falha repetida. Os resultados da IA continham lacunas lógicas, onde havia uma falta de justificação para a matemática, contendo suposições evolutivas e continuando a criar uma visão errada, apesar de criar resultados contraditórios.
Isso inclui uma instância específica USAMO 2025 Edição 5. Esse problema solicitou aos modelos que encontrassem todos os números positivos de “K”, como um cálculo específico incluído na quantidade de “K” para a força de “K” é sempre o resultado de um número, mesmo que não importa qual “n” numérico positivo tenha sido usado. Nesta edição, o modelo QWQ da rainha cometeu um erro notável: deturpou possibilidades não judiciais nessa fase, onde a declaração do problema lhes permitia. Devido a esse erro, o modelo foi atraído para uma resposta final falsa, mas os termos necessários foram identificados no processo de raciocínio.



